Свяжитесь с нами
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Mixtral, DeepSeek-V2 и другие. Как работает «комитет экспертов» внутри одной модели и в чем выгода.
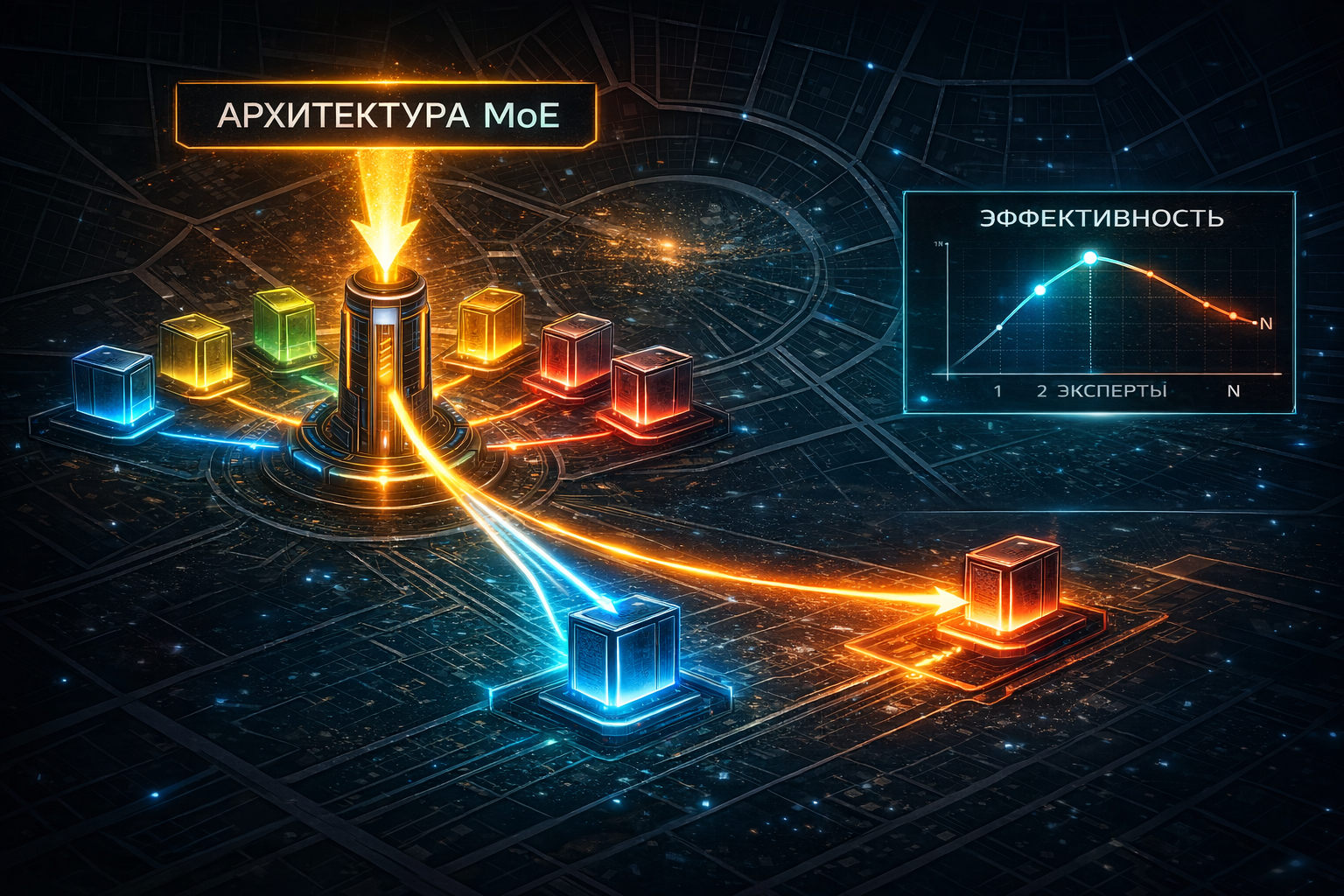
Вы смотрите на технические спецификации и видите: «Mixtral 8x7B» — 56 миллиардов параметров?! Но требования к памяти заявлены как для модели 13B. Это не магия, это архитектура Mixture of Experts (MoE) — один из самых прорывных трендов, который меняет баланс между качеством и стоимостью инференса. Давайте разберем, что это и нужно ли это вам.
Принцип работы: «Мозг» с распределением задач
Представьте, что у вас есть не один универсальный гений-модель, а команда из 8 узких экспертов:
Эксперт по коду
Эксперт по математике
Эксперт по естественным наукам
Эксперт по юриспруденции
И т.д.
И есть маршрутизатор (router) — маленькая нейросеть, которая для каждого входного токена (слова) решает: каким экспертам (обычно 2 из 8) отдать этот токен на обработку?
На входе: «Напиши функцию на Python, которая вычисляет факториал, и объясни математическую формулу.»
Маршрутизатор: Токен Python → Эксперт по коду. Токен функцию → Эксперт по коду. Токен факториал → Эксперт по математике и по коду. Токен формулу → Эксперт по математике.
Ключевая суперсила MoE: Активируются только часть параметров!
В модели Mixtral 8x7B на самом деле 8 «экспертов» по 7 миллиардов параметров каждый + маленький маршрутизатор. Но для обработки одного токена работают только 2 эксперта (это top_k параметр). Поэтому:
Общее число параметров: 8 * 7B = 56B (очень много знаний, SOTA-качество).
Активных параметров за раз: 2 * 7B = ~13B (требования к памяти и вычислениям как у модели 13B!).
Итог: Вы получаете качество, близкое к огромной модели, по стоимости инференса средней модели.
Плюсы архитектуры MoE:
Невероятная эффективность: Главное преимущество. Лучшее качество/стоимость на рынке.
Масштабируемость: Чтобы увеличить «ум» модели, можно добавлять новых экспертов, а не делать всю сеть глубже/шире.
Потенциальная специализация: Эксперты неявно учатся специализироваться на разных типах данных, что может дать более точные ответы в нишевых областях.
Минусы и сложности:
Трудности обучения: Обучить стабильную MoE-модель с нуля — очень дорого и сложно. Нужны гигантские датасеты и вычислительные ресурсы. Поэтому их выпускают только гиганты (Mistral AI, DeepSeek).
Проблемы с fine-tuning: Дообучение MoE-модели — нетривиальная задача. Нужно аккуратно обновлять и маршрутизатор, и экспертов, чтобы не сломать баланс. Техники PEFT (LoRA) для MoE все еще развиваются.
«Голод экспертов» (Expert Starvation): Если маршрутизатор полюбит 1-2 экспертов и будет отправлять им все запросы, остальные эксперты деградируют. Нужны специальные техники регуляризации при обучении.
Высокие требования к памяти для загрузки: Хотя активных параметров мало, загрузить в память нужно все экспертов (все 56B). Это требует много VRAM. Но современные техники (например, загрузка экспертов с SSD «на лету») решают эту проблему.
Основные модели MoE на рынке:
Mixtral 8x7B / 8x22B (Mistral AI): Лидер направления. 8x7B — эталон баланса. Работает быстрее и качественнее, чем Llama 2 70B, при ресурсах как у 13B модели.
DeepSeek-V2 (DeepSeek AI): 236B полных параметров, но только 21B активных за шаг. Одна из самых умных и эффективных моделей в мире на момент выхода.
Qwen1.5-MoE (Alibaba): Вариация на тему.
Ждем MoE-версий от Meta (Llama) — это будет следующий большой шаг.
Когда вам НУЖНА модель MoE?
Вам критически важно качество, сравнимое с большими плотными моделями (70B+), но нет бюджета/инфраструктуры для их инференса.
У вас разнородные задачи (часть запросов — код, часть — текст, часть — анализ). MoE может лучше распределить нагрузку.
Вы готовы работать с чуть более сложным стеком (специфичные оптимизации для загрузки) ради экономии.
Вы не планируете глубокий fine-tuning, а будете использовать out-of-the-box или с легким промпт-инжинирингом/RAG.
Когда вам, возможно, НЕ нужна MoE (пока что):
У вас узкая, специфичная задача (только классификация текста, только NER). Плотная модель 7B-13B может быть проще и дешевле.
Вы планируете серьезный fine-tuning или дообучение с нуля. С плотными моделями это проще и предсказуемее.
У вас экстремальные ограничения по памяти VRAM. Хоть активные параметры и малы, полная загрузка 8x7B требует ~90GB+ VRAM (без оптимизаций). Для 8x22B — сотни гигабайт.
Практический совет:
Для большинства производственных задач, начинающих выходить за рамки возможностей Llama 3 8B, модель Mixtral 8x7B (или ее будущие аналоги) — это следующий логичный и экономически оправданный шаг. Она предлагает «золотую середину» 2024-2025 годов.
Вывод:
MoE — не будущее, а настоящее эффективного инференса. Эта архитектура ломает парадигму «больше параметров = невыносимо дорого». Она позволяет малым и средним компаниям использовать модели с качеством топ-уровня. Если ваша задача требует «ума», а бюджет ограничен — присмотритесь к MoE. Начните с тестирования Mixtral 8x7B на вашем бенчмарке — высока вероятность, что она станет вашим рабочим выбором на долгое время.


