Свяжитесь с нами
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Когда классический Transformer неэффективен. MoE, ранний выход и другие техники для максимальной производительности.
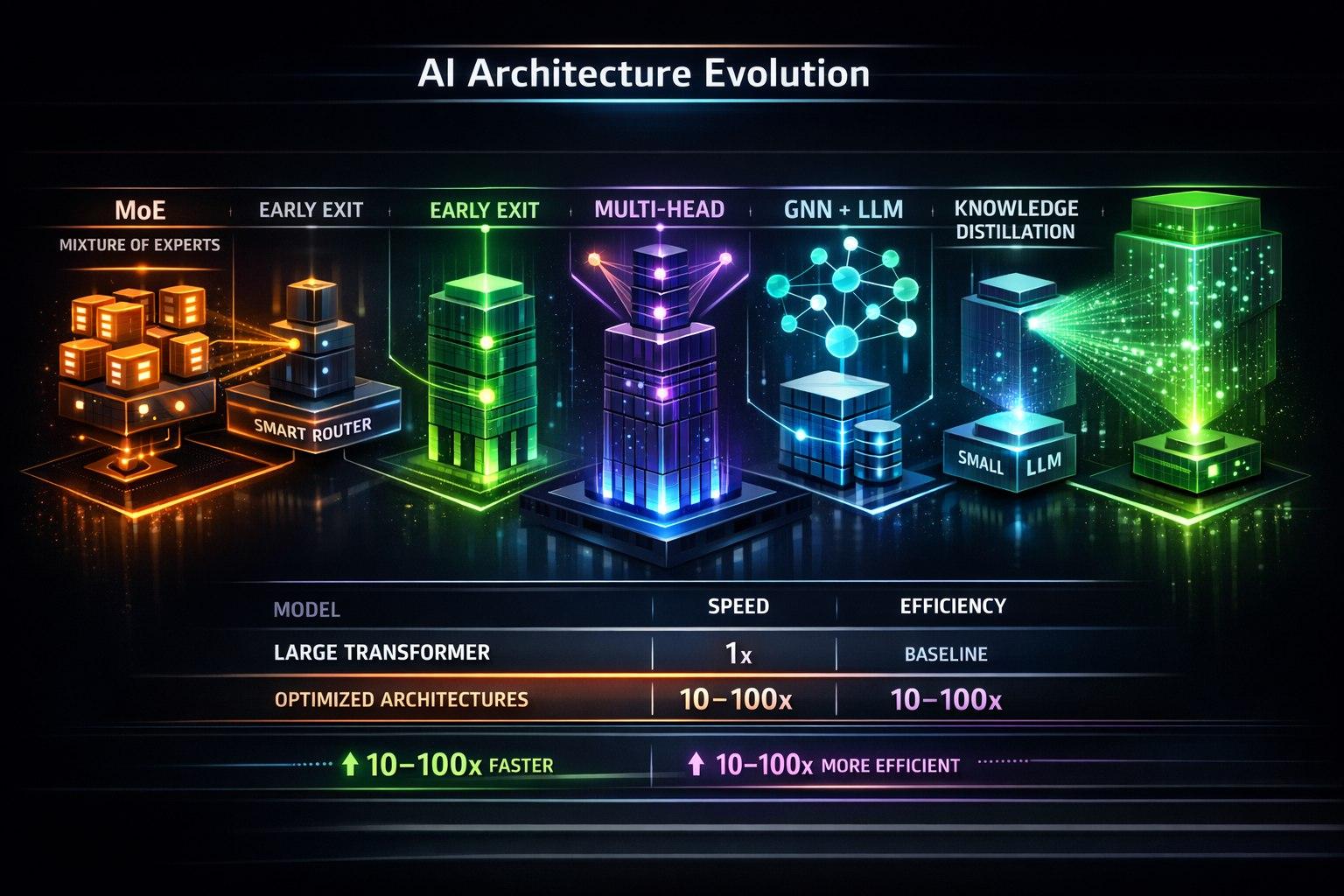
Классическая архитектура Transformer (как в Llama, Phi) — универсальна, но не всегда оптимальна для узкоспециализированных онтологических задач. Когда каждая миллисекунда и мегабайт памяти на счету, нужны специализированные архитектуры.
Проблема: Transformer "стреляет из пушки по воробьям"
Для простой классификации ("Это вопрос о цене или доставке?") не нужны 32 слоя внимания и FFN-сети. Это избыточно.
Архитектура 1: Mixture of Tiny Experts (Мини-MoE)
Идея: Вместо одного большого Transformer'а — несколько крошечных "экспертов" (1-100M параметров), каждый для своей подзадачи онтологии.
Реализация для онтологии товаров:
Эксперт по категориям (50M): Классифицирует товар.
Эксперт по атрибутам (30M): Извлекает цвет, размер, материал.
Эксперт по совместимости (70M): Проверяет совместимость товаров.
Маршрутизатор (5M): Определяет, какие эксперты нужны для запроса.
Преимущества:
Параллелизация: Эксперты работают параллельно.
Экономия: Активируются только нужные эксперты.
Обновляемость: Можно дообучать одного эксперта, не трогая других.
Архитектура 2: Ранний выход (Early Exit)
Идея: Не прогонять весь 32-слойный Transformer для простых запросов. Выходить раньше, если модель уже "уверена".
Как работает:
На выходах промежуточных слоев (например, 6, 12, 18) ставятся классификаторы.
Если классификатор на 6-м слое выдаёт уверенность >95% — возвращаем ответ сразу.
Для сложных запросов идём до конца.
Для онтологии: Простые фактологические запросы обрабатываются за 6 слоёв, сложные логические — за все 32.
Архитектура 3: Многоголовая классификация (Multi-Head для онтологии)
Задача: Нужно определить несколько аспектов одновременно (интент + сущности + тональность).
Решение: Общая энкодерная часть + несколько "голов" для разных задач.
Архитектура 4: Нейросетевые онтологические графы (Graph Neural Networks + Tiny LLM)
Для сложных онтологий с множеством отношений:
GNN обрабатывает граф онтологии, создавая векторные представления сущностей.
Маленькая LLM (1-3B) получает на вход:
Запрос пользователя
Векторы релевантных сущностей из GNN
LLM генерирует ответ, используя семантику онтологии.
Архитектура 5: Дистилляция онтологических знаний (Knowledge Distillation)
Задача: Ужать большую онтологическую модель (например, 70B) в маленькую (3B) с минимальной потерей качества.
Процесс:
Учитель: Большая модель, обученная на полной онтологии.
Ученик: Маленькая модель (3B).
Обучение: Ученик учится не только на правильных ответах, но и на распределении вероятностей учителя.
Практический кейс: Система диагностики по онтологии симптомов (7→1B)
Исходная система: GPT-4 (1700B), latency 2с, $0.01 за запрос.
Цель: Модель <1B, работающая на CPU, latency <100мс.
Решение:
Архитектура: Early Exit Transformer (12 слоёв, выходы на 4 и 8 слое).
Данные: 50K примеров "симптомы → возможные причины" из медицинской онтологии.
Обучение: Дистилляция с GPT-4 + дообучение.
Квантование: Q4_K_M → размер 650 МБ.
Результат:
Качество: 92% против 96% у GPT-4 для простых случаев.
Latency: 75 мс на CPU.
Стоимость: В 1000 раз дешевле в эксплуатации.
Развертывание: Может работать на мобильном устройстве врача.
Инструменты для создания специализированных архитектур:
JAX/Flax: Для экспериментальных архитектур.
Tinygrad / MLX (Apple): Для сверхэффективного инференса.
Apache TVM: Для компиляции моделей под конкретное железо.
ONNX Runtime: Для кроссплатформенного развертывания.
Когда какую архитектуру выбирать:
| Задача | Рекомендуемая архитектура | Пример размера |
|---|---|---|
| Простая классификация | Early Exit Transformer | 100M-500M |
| Извлечение структуры | Multi-Head BERT | 200M-1B |
| Сложная онтология с отношениями | GNN + Tiny LLM | GNN: 50M, LLM: 1-3B |
| Много независимых подзадач | Mixture of Tiny Experts | 50-200M на эксперта |
| Максимальное качество в маленькой форме | Дистилляция + MoE | 1-3B |
Вывод:
Не пытайтесь впихнуть сложную онтологию в стандартную архитектуру LLM. Специализированные архитектуры дают выигрыш 10-100x в производительности при том же или лучшем качестве для узких задач. Инвестируйте время в проектирование архитектуры, которая отражает структуру вашей онтологии: если знания иерархичны — используйте ранний выход, если модульны — MoE, если графовые — GNN. Маленькая, но правильно спроектированная модель превзойдёт большую универсальную в своей предметной области.


