Свяжитесь с нами
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
От резюме full-stack разработчика до PhD по NLP — как отличить реальные навыки от красивых слов в эпоху хайпа вокруг AI.
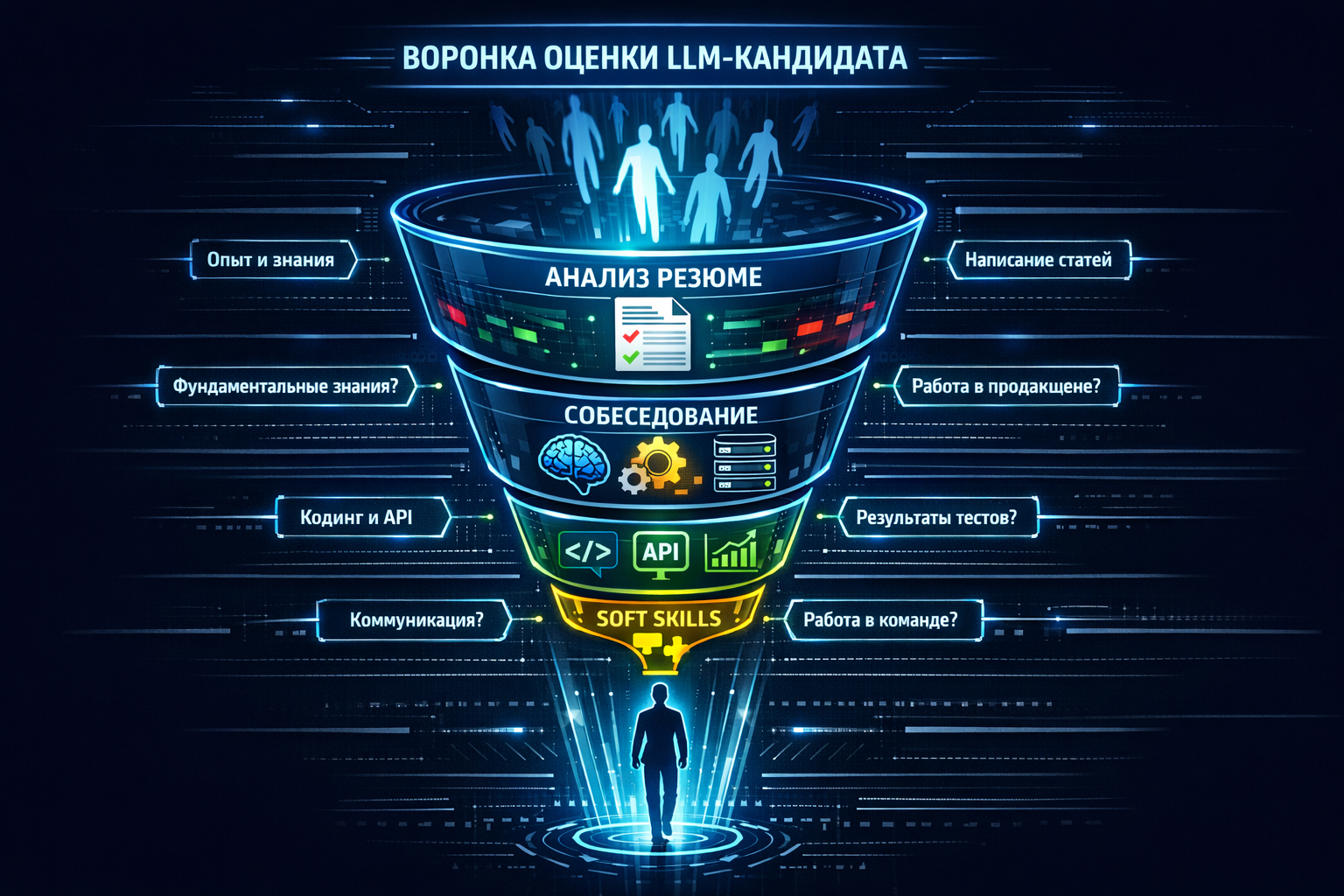
Рынок перегрет. В каждом втором резюме написано «опыт с GPT», «prompt engineering», «fine-tuning LLM». Как не нанять «специалиста», который всего лишь умеет пользоваться ChatGPT Plus? Нужны правильные фильтры и конкретные вопросы, которые вскроют реальную глубину знаний.
Этап 1: Анализ резюме — красные и зеленые флаги
Зеленые флаги (Хорошие признаки):
Конкретные проекты с открытым кодом: Ссылка на GitHub с репозиториями, где виден код работы с Transformers, fine-tuning, RAG. Даже если это учебные проекты — это уже плюс.
Упоминание конкретных библиотек и фреймворков: Не просто «знаю Python», а PyTorch, Transformers (Hugging Face), vLLM, LangChain/LlamaIndex, Weaviate/Pinecone, Docker/K8s.
Конкретные модели: «Fine-tuned Llama 2 7B на датасете ... с использованием QLoRA» — лучше, чем «работал с большими языковыми моделями».
Метрики и результаты: «Достиг улучшения accuracy на 15%», «снизил latency инференса в 2 раза».
Участие в соревнованиях (Kaggle, хакатоны) по NLP.
Красные флаги (Тревожные признаки):
Размытые формулировки: «Опыт работы с AI», «Использовал нейросети для решения бизнес-задач» без деталей.
Акцент только на промпт-инжиниринг: Если в резюме это подается как основная и единственная компетенция — кандидат, скорее всего, поверхностен.
Отсутствие ссылок на код: Для инженерной роли это must-have.
«Я обучил модель GPT-3 с нуля»: Для частного лица это практически невозможно (стоимость > $1M). Скорее всего, речь о fine-tuning.
Этап 2: Собеседование — структура и правильные вопросы
Блок 1: Фундаментальные знания (Обязательно для ML Engineer)
Цель — проверить, понимает ли кандидат, как работает инструмент, которым он пользуется.
Вопрос 1: «Объясни, как работает механизм внимания (attention) в Transformer, и почему он так важен для LLM?» Ждем ответ про Query, Key, Value, scaled dot-product и способность модели фокусироваться на разных частях контекста.
Вопрос 2: «В чем разница между дообучением (fine-tuning) и обучением с нуля (pre-training)? Какие методы эффективного дообучения (PEFT) ты знаешь?» Ждем ответ про полный fine-tuning, LoRA, QLoRA, их плюсы/минусы.
Вопрос 3: «Что такое эмбеддинг (embedding)? Как он используется в RAG? Какие модели для эмбеддингов ты использовал?» Ждем ответ про vector space, семантический поиск, упоминание конкретных моделей (OpenAI text-embedding, sentence-transformers).
Блок 2: Практические навыки и опыт (Кейсовые вопросы)
Цель — понять, как кандидат подходит к реальным задачам.
Вопрос 1 (Архитектурный): «Представь, тебе нужно создать AI-ассистента по документации компании. Опиши высокоуровневую архитектуру решения. Какие компоненты понадобятся?» Ждем упоминания: сбор данных, чанкование, векторизация, векторная БД, LLM, промпт-шаблоны, API. Хороший кандидат спросит уточняющие вопросы (объем данных, требования к latency).
Вопрос 2 (Проблемный): «Ты развернул RAG-систему, но пользователи жалуются, что ответы иногда нерелевантны («галлюцинации»). Как будешь диагностировать и исправлять проблему?» Ждем системный подход: проверка качества чанкования, recall векторного поиска, анализ промптов, добавление reranking, использование few-shot примеров.
Вопрос 3 (Оптимизация): «Модель в продакшне стала отвечать слишком медленно и дорого. Какие шаги предпримешь для оптимизации?» Ждем: анализ промптов (токены), кэширование, выбор более легкой модели, аппаратные оптимизации (квантование, использование vLLM), model routing.
Блок 3: Инженерия и продакшн (Для MLE и ML Ops)
Вопрос 1: «Как бы ты развернул модель Llama 3 8B в продакшне, чтобы обслуживать 100 RPS (запросов в секунду)? Опиши инфраструктуру.» *Ждем: Docker-образ, оркестратор (K8s), инференс-сервер (vLLM, TGI), autoscaling, load balancer, мониторинг. *
Вопрос 2: «Как организовать CI/CD для ML-пайплайна, который включает в себя обновление векторной БД при появлении новых документов?» Ждем: пайплайн в Airflow/Prefect, версионирование данных, тестирование, canary-деплой.
Вопрос 3: «Какие метрики нужно мониторить у LLM в продакшне, кроме latency и ошибок 5xx?» Ждем: cost per request, качество ответов (через LLM-as-a-Judge), токсичность, релевантность RAG (recall).
Этап 3: Практическое задание (Take-home test)
Не давайте абстрактных задач! Задание должно максимально приближать к реальной работе.
Плохое задание: «Напиши эссе о будущем LLM» или «Придумай 10 промптов для...».
Хорошее задание: «Вот датасет из 1000 вопросов-ответов нашей поддержки (анонимизированный) и 10 новых вопросов для теста. Сделай прототип: 1) Загрузи данные в векторную БД (можно локальную, например, Chroma). 2) Настрой простой RAG-пайплайн с любой open-source LLM (например, через Ollama или Hugging Face). 3) Напиши API endpoint, который принимает вопрос и возвращает ответ. 4) Оцени качество на 10 тестовых вопросах, посчитав какую-то метрику (можно просто accuracy). Пришли код и короткий отчет.»
Что оцениваем: Умение работать с кодом и данными, выбор инструментов, качество кода, умение оценить результат.
Этап 4: Оценка soft skills
Для LLM-проектов критически важны:
Коммуникация: Сможет ли он объяснить сложные концепции Product Manager'у и эксперту?
Гибкость и любознательность: Сфера меняется каждый месяц. Готов ли он постоянно учиться?
Системное мышление: Видит ли он проект как систему, а не как набор отдельных скриптов?
Работа с неопределенностью: LLM часто ведут себя непредсказуемо. Как он реагирует на это?
Специфика для других ролей:
Data Engineer for AI: Спрашивайте про опыт построения пайплайнов для неструктурированных данных, работу с векторными БД, оптимизацию обработки больших текстов.
ML Ops Engineer: Углубляйтесь в инфраструктуру, оркестрацию, мониторинг, обеспечение отказоустойчивости.
Product Manager: Спрашивайте не про технологии, а про умение работать с метриками, приоритизацию, управление ожиданиями, знание юнит-экономики AI-продукта.
Вывод для рекрутера и hiring manager:
Главный принцип — теория + практика + инженерия. Не давайте сойти соискателю с дистанции на красивых словах. Просите объяснять фундаментальные концепции, решать архитектурные кейсы и показывать код. И помните: настоящий специалист в этой области горит своим делом. Он будет с удовольствием рассказывать о последней статье от Meta или о том, как он победил в соревновании по оптимизации инференса. Найдите этого фанатика — и вы найдете своего ключевого сотрудника.


