Свяжитесь с нами
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Когда ваша языковая модель — это не один файл .pth, а сложная распределенная система. Как управлять ее жизненным циклом.
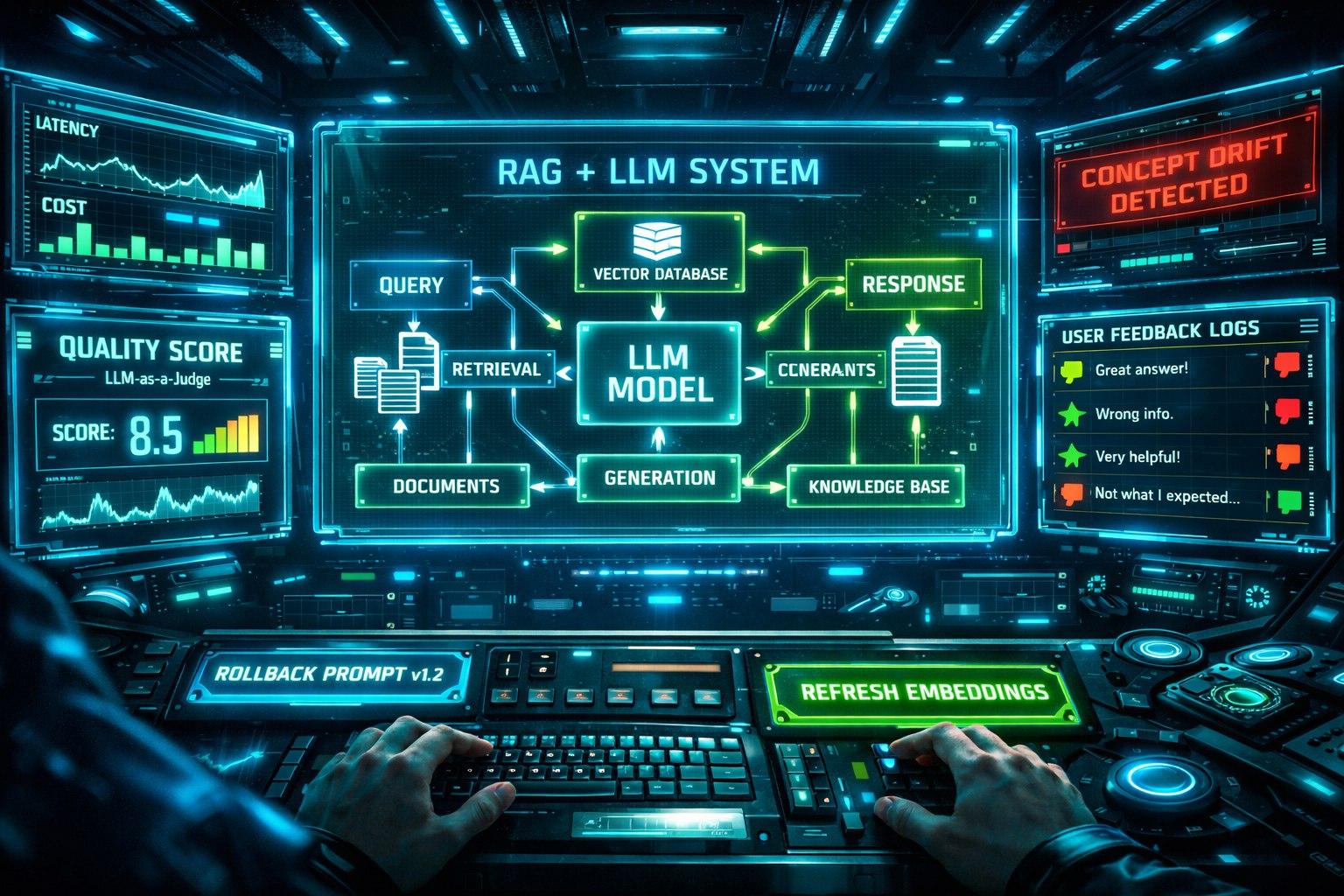
Вы запустили в продакшн LLM-ассистента. Что дальше? Как обновить эмбеддинг-модель в RAG без простоев? Как откатить новую версию промпта, которая ухудшила качество? Как отслеживать, что ответы модели остаются релевантными? Традиционная MLOps для классических ML-моделей (скоринг кредитов, предсказание цены) не работает. Нужна специализированная LLM Ops, которая учитывает всю специфику: промпты, векторные поиски, контекстные окна, «галлюцинации».
LLM Ops — это управление системой, а не одной моделью.
Ключевые компоненты платформы LLM Ops:
1. Управление данными и признаками (Data & Feature Management)
Версионирование тренировочных данных: Для fine-tuning моделей. Каждая версия датасета — это снапшот в Lakehouse (см. ст. 14).
Feature Store в действии: LLM-агенты используют актуальные фичи о пользователях/продуктах из Online Store. При этом версия фичей должна быть согласована с версией модели.
Векторные БД как часть пайплайна данных: Должна быть возможность полностью воспроизвести состояние векторной БД на конкретную дату. Через версионирование индексов или скрипты пересоздания из данных в Lakehouse.
2. Управление артефактами модели (Model & Prompt Registry)
Модельный реестр (Model Registry) теперь хранит не только веса fine-tuned LLM, но и:
Ссылки на базовую модель (например, meta-llama/Meta-Llama-3.1-8B-Instruct).
Версию эмбеддинг-модели, используемой в RAG.
Промпты и их версии! Каждый промпт — это production-артефакт. Изменения в промпте = новая версия развертывания.
Четкий пайплайн продвижения: dev -> staging -> prod. Промпт или модель проходят через тестирование на валидационной выборке и canary-развертывание.
3. Инференс и обслуживание (Serving & Inference)
Специализированные инференс-серверы: Не просто REST API, а серверы, которые умеют:
Динамически подставлять в промпт контекст из RAG и фичи из Feature Store.
Работать с несколькими моделями (легкая для простых запросов, тяжелая для сложных) и маршрутизировать запросы.
Кэшировать семантически похожие запросы и ответы.
Инфраструктура как код для LLM: Описание всей стека (векторная БД, инференс-сервис, модель) в Terraform или Helm-чартах для воспроизводимости.
4. Всеобъемлющий мониторинг и observability
Метрики инфраструктуры: Загрузка GPU, latency инференса, частота ошибок API.
Метрики затрат: Стоимость токенов в разрезе по моделям и пользователям.
Метрики качества (самое сложное):
Качество RAG: Recall, точность извлечения чанков, количество «пустых» ответов.
Качество ответов LLM: Используются сторонние маленькие модели-оценщики (LLM-as-a-Judge). Например, после каждого ответа ваша система отправляет запрос и ответ GPT-4: «Оцени релевантность ответа вопросу от 1 до 5». Или: «Содержит ли ответ токсичные высказывания? Да/Нет».
Трекшн пользовательского feedback: Кнопки «лайк/дизлайк» — это золотые данные для дообучения.
Логирование для воспроизводимости (Non-negotiable): В лог на каждый запрос должно попасть: финальный промпт (с контекстом), использованные чанки RAG, полный ответ модели, версии всех компонентов, user_id. Без этого дебагг невозможен.
5. Автоматическое переобучение и обновление (Retraining & Refreshing)
Детекция дрейфа данных (Data/Concept Drift): Если оценки релевантности (от LLM-as-a-Judge) или feedback пользователей начинают падать — это сигнал.
Автоматический пересчет эмбеддингов: При добавлении новых документов в источник или при обновлении эмбеддинг-модели.
Автоматический fine-tuning: Накопились данные с негативным фидбеком? Система может автоматически подготовить датасет для дообучения, запустить тренировку на тестовом кластере и предложить инженеру протестировать новую версию.
Современные платформы:
MLflow + кастомные плагины: можно расширить для работы с промптами.
Kubeflow: Для оркестрации сложных пайплайнов (обучение, инференс).
Weights & Biases (W&B), Neptune.ai : Для трекинга экспериментов с промптами и их версиями.
Специализированные: Arize AI, WhyLabs, LangSmith (от LangChain) — предлагают инструменты именно для мониторинга LLM.
Вывод для Head of ML/AI:
LLM Ops — это логичное и необходимое развитие MLOps. Это дисциплина, которая превращает ваши эксперименты с LLM в надежные, управляемые и постоянно улучшающиеся бизнес-системы. Инвестиции в такую платформу — это инвестиции в скорость итераций, контроль качества и, в конечном счете, в доверие бизнеса к вашим AI-решениям. Без LLM Ops ваша продвинутая LLM-система останется рискованным прототипом.


