Свяжитесь с нами
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Как избежать хаоса, когда в одной модели «возраст» — это число лет, а в другой — категория. Централизованное управление данными для обучения и инференса.
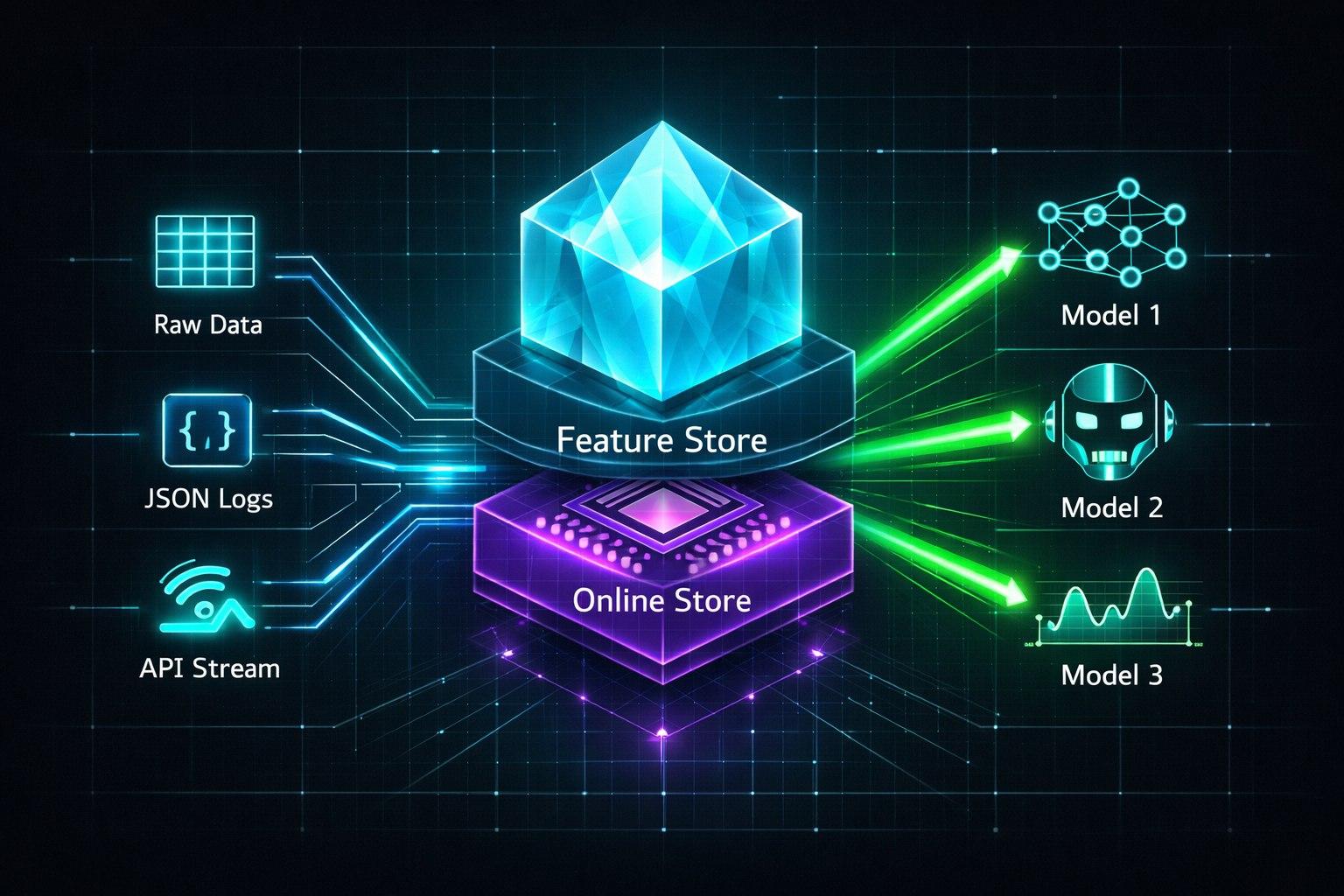
Ваша команда запускает три модели: одна предсказывает отток (churn), другая рекомендует продукты, третья (LLM) персонализирует ответы. Все они используют данные о клиентах. Но Data Scientist для churn-модели взял «возраст» из одной таблицы, а инженер для рекомендаций — из другой, где его посчитали по-другому. LLM вообще получила сырые JSON из логов. Результат: модели работают несогласованно, их невозможно сравнивать, а обновление данных превращается в кошмар. Решение — Feature Store (Хранилище признаков).
Что такое Feature Store? Это «библиотека готовых данных» для AI.
Представьте, что вместо того чтобы каждый раз готовить сырые ингредиенты, повара (Data Scientists) приходят на кухню и берут уже нарезанные, очищенные и проверенные компоненты (фичи) из общего холодильника.
Зачем это нужно в эпоху LLM?
Консистентность: Обеспечивает, что в обучении (offline) и в реальной работе модели (online) используются одни и те же данные, вычисленные одинаковым способом.
Эффективность: Исключает дублирование работы. Фича «средний чек за 30 дней» вычисляется один раз, а используется в десятке моделей.
Скорость выдачи (Low-Latency Serving): Для инференса в реальном времени (например, для LLM-агента, решающего, какой оффер показать) фичи должны быть доступны за миллисекунды. Feature Store решает эту задачу.
Управление жизненным циклом: Версионирование фич, отслеживание их актуальности (data drift), управление доступом.
Ключевые компоненты Feature Store:
Offline Store (Хранилище для обучения): Обычно большая, медленная, дешевая база данных (HDFS, BigQuery, S3 + Iceberg/Delta Lake). Содержит исторические значения фич за длительный период. Нужна для обучения моделей и анализа.
Online Store (Хранилище для инференса): Быстрая, низколатентная БД (Redis, Cassandra, DynamoDB, специальные решения like Feast Online Store). Содержит актуальные значения фич для каждого объекта (например, для каждого user_id). LLM-агент запрашивает отсюда данные в реальном времени.
Трансформации (Transformation Engine): Код (Python-функции, SQL), который преобразует сырые данные в фичи. Он должен исполняться одинаково при наполнении offline- и online-хранилищ.
Реестр (Registry): Каталог всех фич с описанием, версиями, метаданными (тип данных, создатель, SLA свежести).
Как Feature Store работает с LLM и RAG?
Сценарий: LLM-ассистент в банковском чате отвечает на вопрос: «Какие у меня есть предложения по кредиту?»
Промпт LLM включает шаблон: «Проанализируй запрос клиента. Его профиль: {features}. Доступные кредитные продукты: {products}»
Система в реальном времени обращается к Online Feature Store по user_id и получает:
credit_score: 720
avg_monthly_balance_last_90d: 150000
has_mortgage: false
segment: premium
Эти структурированные фичи + запрос пользователя передаются в LLM, которая генерирует персонализированный ответ, основываясь на точных данных, а не на догадках.
При этом для обучения моделей, которые оценивают эффективность этого ассистента, используются те же самые фичи, но взятые из Offline Store.
Популярные решения: Feast, Hopsworks, Tecton
Feast (Open Source): Относительно простой, хорош для старта. Прямая интеграция с популярными облачными хранилищами.
Hopsworks: Более комплексная платформа с Feature Store как одной из компонент.
Tecton (SaaS): Enterprise-решение «из коробки» с высокой производительностью, но и высокой стоимостью.
Вывод для Head of Data:
Feature Store — это не просто «очередная БД». Это архитектурный паттерн и платформа, которые ставят данные в центр вашей AI-стратегии. Внедрение Feature Store — это инвестиция в скорость разработки, надежность продакшн-систем и, в конечном счете, в качество всех ваших AI-продуктов, от классических ML до продвинутых LLM-агентов. Это мост между миром данных и миром моделей.


